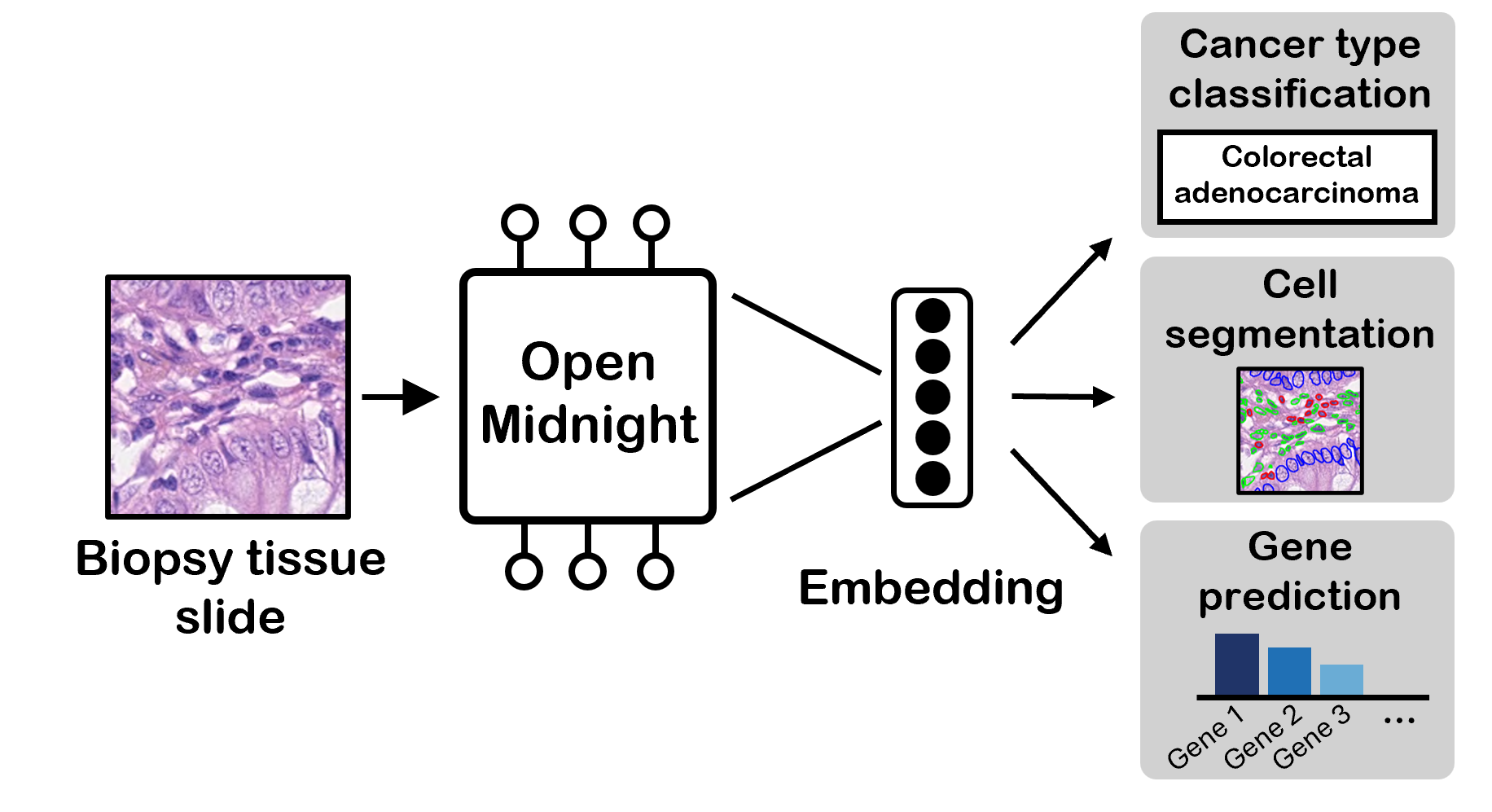
TL;DR: We present OpenMidnight, a replication and improvement of the Midnight pathology foundation model, that achieves state-of-the-art performance across multiple benchmarks while being trained on just 12,000 whole-slide images for only $1.6K. We demonstrate that foundation models for computational pathology do not require massive scale to achieve top performance, and we release the full training pipeline, code, and model weights to accelerate research in this field.
Introduction
Examining patient tissue under a microscope by a pathologist is an essential step in diagnosing and treating cancer and other diseases. Specifically, a tissue biopsy is taken, and the sample is stained and affixed to a glass slide for the pathologist to analyze. The pathologist performs various tasks, such as detecting abnormal cells and determining the severity of disease. In order to accurately assess the tissue slide, the pathologist has to observe the shape of cells, the organization of cells in the tissue, and more.
Computational pathology (CPath), which is the application of AI to digitized whole-slide images (WSIs), has emerged to augment these workflows. AI systems have been developed for tasks like tumor detection, grading,
While many early CPath systems were "narrow" deep-learning models trained for a single task (some methods currently approved by the FDA and used in clinical practice), the field is increasingly exploring foundation models. Rather than training a new model for every task, a single pre-trained foundation model can be adapted to many downstream applications in CPath. Companies like Microsoft,
The prevailing wisdom is that foundation models should improve with scale,
At Sophont, our initial steps towards training our own pathology foundation model began with a replication of Kaiko.AI's Midnight model, fully open-sourced, including training code and model weights. Through some additional minor pipeline improvements, we achieve state-of-the-art (SOTA) average performance across a variety of benchmarks. We estimate that our model consumed 16× fewer GPU hours and completed in one-quarter of the time it took to train Midnight (single-node 8×H100 for 3.5 days vs. Midnight's 32×H100 for 14 days), costing only $1.6K USD assuming a cost of $2.5/H100/hr (exact compute costs may vary).
In this post, we detail how our Midnight replication works and what it means for the field that this model could outperform the competition without scale.
We release this model as OpenMidnight, the first model in our series of pathology foundation models. We open-source the model weights on 🤗 Hugging Face, and the training code on 💻 GitHub. If you're interested in trying out the model, we have a 🧪 demo.
Results
We evaluate OpenMidnight on a variety of benchmarks supported by eva, an evaluation suite released by Kaiko.ai. These benchmarks cover multiple different downstream proxy tasks, from nucleus segmentation to tumor patch classification to cancer subtyping of WSIs. We also evaluate OpenMidnight on the HEST
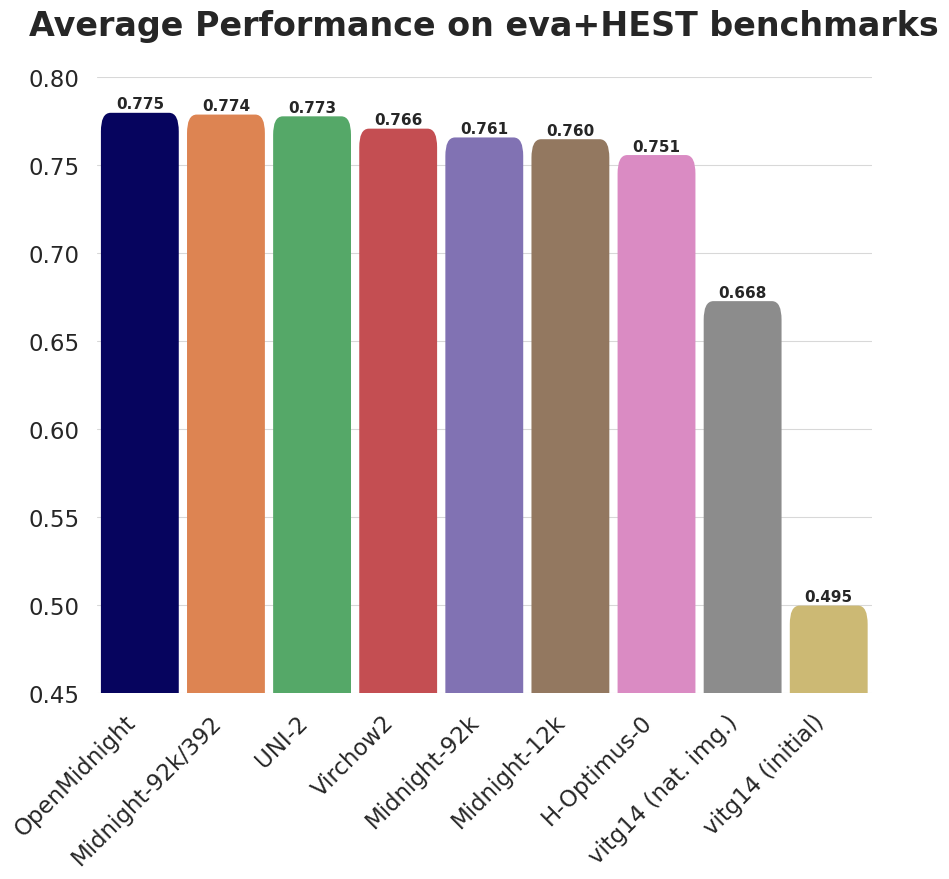
These results show that OpenMidnight's performance is comparable or superior to all other models on all tasks, with our average performance being the highest among the tested models (Figure 2). OpenMidnight achieves a new state-of-the-art on both BreakHis and Cam16(small) scoring 0.946 and 0.873 balanced accuracy, respectively, beating the next best model, UNI-2’s 0.860 on BreakHis and 0.873 on Cam16(small).
Again, it is worth highlighting that OpenMidnight was trained with only 12k slides while UNI-2, the third best model, is trained with over 350k slides!
| Model | #WSIs | PCam (10 shots) | BACH | BRACS | BreakHis | CRC-100K | Gleason | MHIST | PCam | Cam16 (small) | Panda (small) | CoNSeP | MoNuSAC | HEST | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenMidnight (Ours) | 12K | 0.790 | 0.916 | 0.661 | 0.873 | 0.961 | 0.817 | 0.844 | 0.938 | 0.946 | 0.652 | 0.631 | 0.655 | 0.390 | 0.775 |
| Midnight | 92K | 0.900 | 0.906 | 0.642 | 0.850 | 0.964 | 0.809 | 0.825 | 0.951 | 0.831 | 0.633 | 0.663 | 0.707 | 0.384 | 0.774 |
| UNI-2 | 350K | 0.887 | 0.914 | 0.661 | 0.860 | 0.965 | 0.778 | 0.823 | 0.949 | 0.868 | 0.659 | 0.628 | 0.644 | 0.414 | 0.773 |
| UNI-2/392 | 350K | 0.821 | 0.917 | 0.663 | 0.829 | 0.965 | 0.791 | 0.849 | 0.927 | 0.858 | 0.653 | 0.629 | 0.659 | 0.407 | 0.767 |
| Virchow2 | 3.1M | 0.851 | 0.884 | 0.624 | 0.823 | 0.966 | 0.778 | 0.861 | 0.936 | 0.865 | 0.656 | 0.639 | 0.676 | 0.398 | 0.766 |
| Midnight 92k | 92K | 0.876 | 0.896 | 0.616 | 0.789 | 0.966 | 0.820 | 0.811 | 0.950 | 0.861 | 0.625 | 0.629 | 0.656 | 0.392 | 0.761 |
| Midnight 12k | 12K | 0.791 | 0.904 | 0.644 | 0.841 | 0.966 | 0.801 | 0.807 | 0.930 | 0.850 | 0.663 | 0.626 | 0.663 | 0.395 | 0.760 |
| H-Optimus-0 | 500K | 0.824 | 0.757 | 0.615 | 0.808 | 0.956 | 0.771 | 0.842 | 0.942 | 0.838 | 0.670 | 0.644 | 0.685 | 0.415 | 0.751 |
| Kaiko-B8 | 29K | 0.786 | 0.872 | 0.617 | 0.825 | 0.957 | 0.748 | 0.828 | 0.917 | 0.831 | 0.642 | 0.643 | 0.686 | 0.373 | 0.748 |
| TCGA-100M | 12K | 0.774 | 0.864 | 0.615 | 0.779 | 0.967 | 0.799 | 0.792 | 0.927 | 0.852 | 0.667 | 0.622 | 0.656 | 0.396 | 0.747 |
| Prov-GigaPath | 171K | 0.852 | 0.766 | 0.616 | 0.821 | 0.951 | 0.720 | 0.831 | 0.942 | 0.791 | 0.660 | 0.626 | 0.687 | 0.393 | 0.743 |
| Hibou-L | 1.1M | 0.804 | 0.811 | 0.637 | 0.740 | 0.933 | 0.763 | 0.839 | 0.952 | 0.823 | 0.634 | 0.645 | 0.668 | 0.388 | 0.740 |
| UNI | 100K | 0.815 | 0.791 | 0.593 | 0.789 | 0.948 | 0.757 | 0.840 | 0.938 | 0.822 | 0.655 | 0.627 | 0.659 | 0.386 | 0.740 |
| UNI/512 | 100K | 0.737 | 0.877 | 0.612 | 0.732 | 0.950 | 0.754 | 0.814 | 0.883 | 0.814 | 0.654 | 0.621 | 0.658 | 0.364 | 0.728 |
| Phikon | 12K | 0.820 | 0.735 | 0.568 | 0.713 | 0.942 | 0.729 | 0.804 | 0.923 | 0.809 | 0.644 | 0.623 | 0.644 | 0.367 | 0.717 |
| Phikon v2 | 60K | 0.741 | 0.734 | 0.600 | 0.716 | 0.939 | 0.755 | 0.784 | 0.893 | 0.803 | 0.631 | 0.626 | 0.645 | 0.375 | 0.711 |
| DINOv2-giant (pretrained) | 0 | 0.719 | 0.725 | 0.583 | 0.832 | 0.935 | 0.744 | 0.862 | 0.874 | 0.507 | 0.382 | 0.564 | 0.614 | 0.342 | 0.668 |
| DINOv2-giant (random) | 0 | 0.649 | 0.473 | 0.411 | 0.427 | 0.748 | 0.464 | 0.569 | 0.755 | 0.566 | 0.308 | 0.461 | 0.428 | 0.172 | 0.495 |
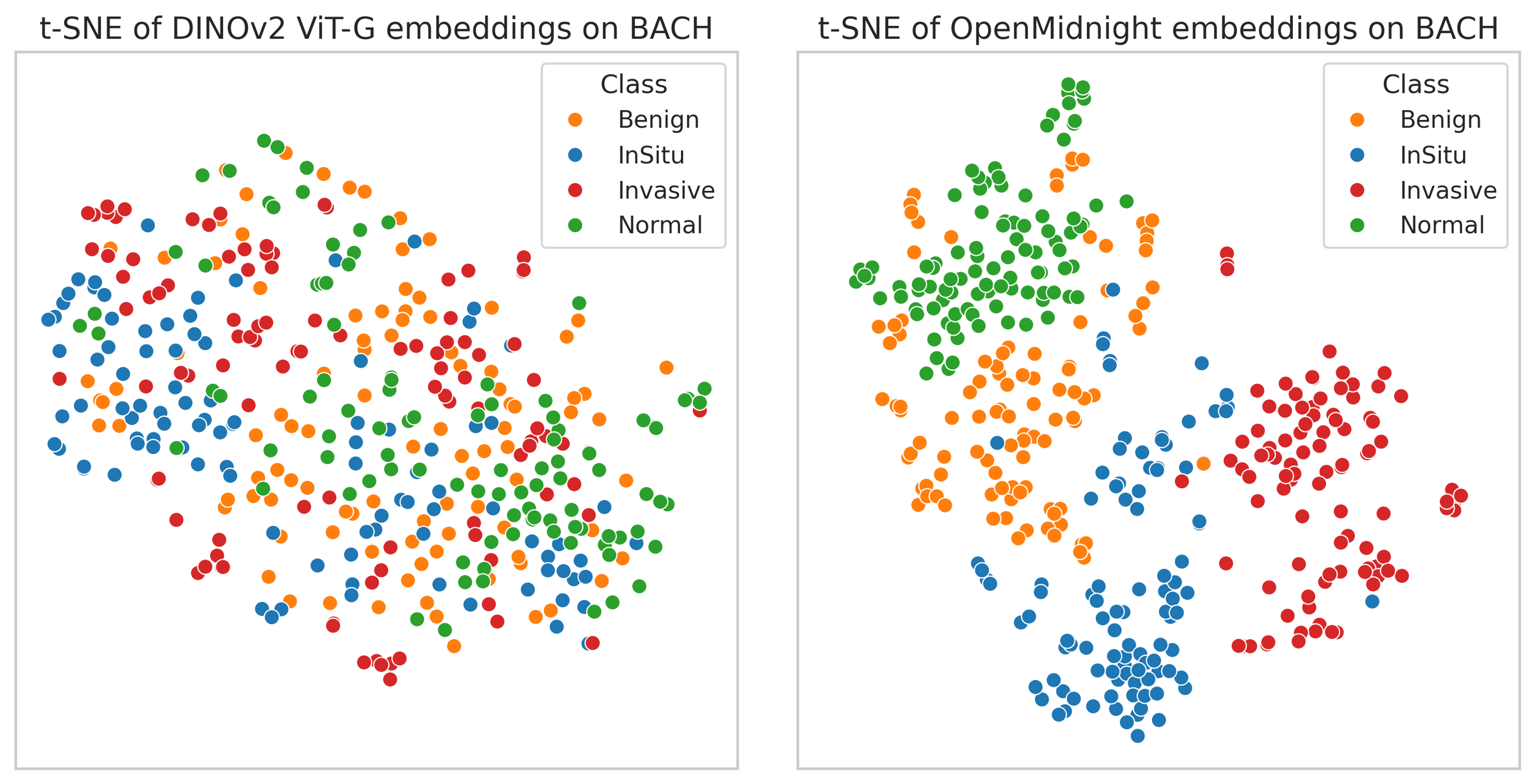
We also qualitatively evaluated the representations learned by OpenMidnight. We took images from the BACH dataset of breast cancer images, passed them through our model, and visualized the embeddings produced by our model using t-SNE (Figure 3). We see a clear separation between different classes and also observe sensible organization of images in the t-SNE space: normal images are closer to benign images than invasive carcinoma images. We also compare these representations to those of a pretrained DINOv2 ViT-G, which lacks any clear separation between classes.
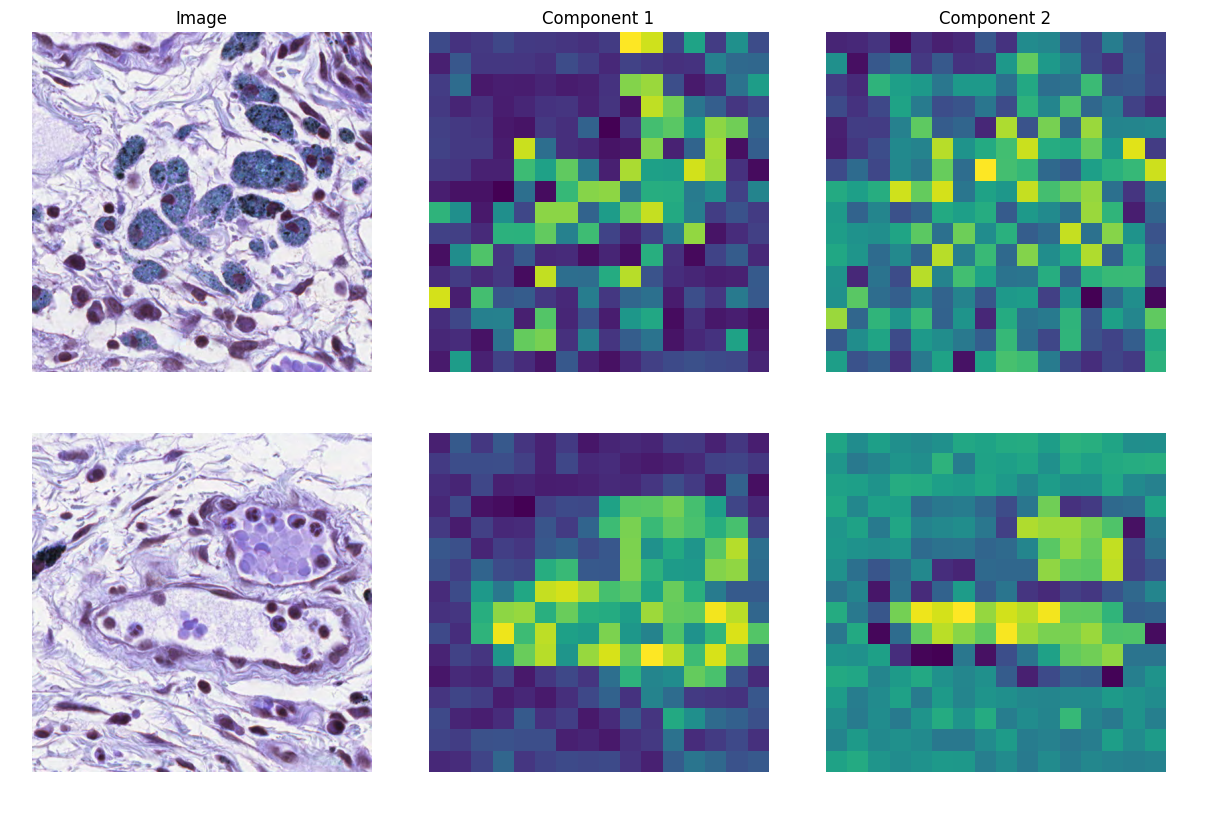
In addition, we perform a principal component feature analysis within single images of the MoNuSAC
How we did it
Our training approach does not differ significantly from other SOTA pathology foundation models, which utilize Meta's DINOv2. However, we mostly follow the original Midnight paper,
We start with a pretrained 1.1B parameter ViT-G DINOv2
OpenMidnight also utilizes augmentations in the Hematoxylin-Eosin-DAB colorspace to increase the diversity of the training data and improve robustness of the model. We also applied these augmentations, but we qualitatively observed that the initial augmentations applied to the image patches during DINOv2 were quite strong, so we decreased the strength of these augmentations.
A majority of the prior works divide up the large whole-slide images into non-overlapping patches of size 224/256 ahead of time, and save them offline. OpenMidnight switched to an online patching approach, where the patches are sampled from the whole-slide image during training. We differ from OpenMidnight by utilizing a variation of offline patching, in which we instead precompute the image patches. However, we still select the patches randomly from within the image, allowing for overlaps. We also perform filtering of non-informative patches like in OpenMidnight.
We train OpenMidnight only on one publicly available dataset: TCGA,
We train using 8 Nvidia-H100 GPUs (80GB memory) at a batch size of 48 per GPU (384 total batch size), for 250K steps, at a learning rate of 2.0e-4 with the AdamW
The current state of pathology foundation models
The surprising performance of OpenMidnight motivates us to take a closer look at the state of pathology foundation models.
All the top CPath foundation models were trained nearly identically, with the biggest difference coming from the private data sources used to train the model. Everyone seems to follow the same recipe of DINOv2 from scratch on patches of whole-slide images, with a few groups identifying benefits from things like swapping out KoLeo
Despite almost identical model architectures, downstream performance across the foundation model landscape is messy. Among the top models, there isn't a clear winner in performance across all the benchmarks (see table above). Additionally, Figure 5 (numbers pulled from prior works) demonstrates that when training pathology foundation models, average performance is not cleanly correlated with the compute used or dataset size.
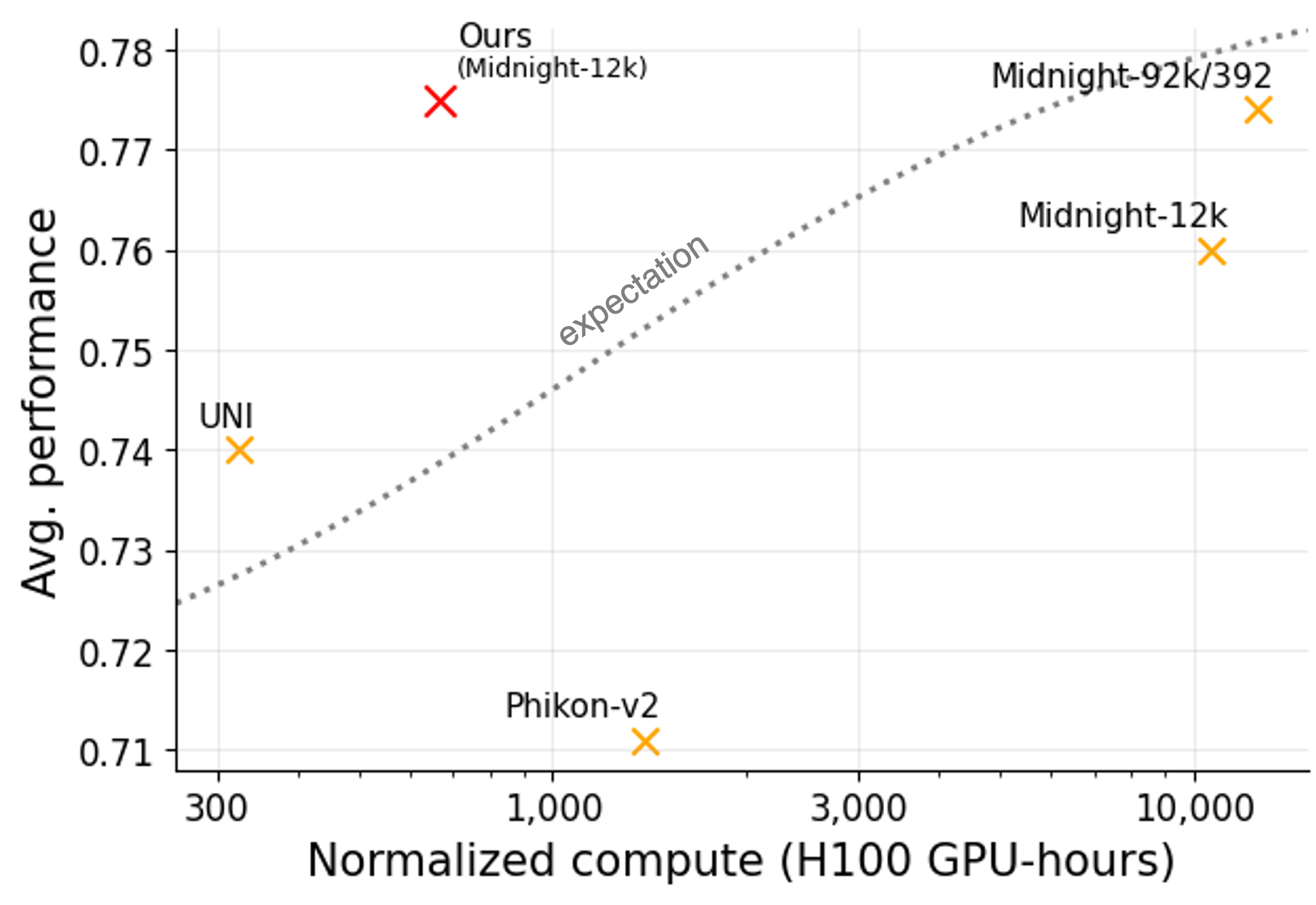
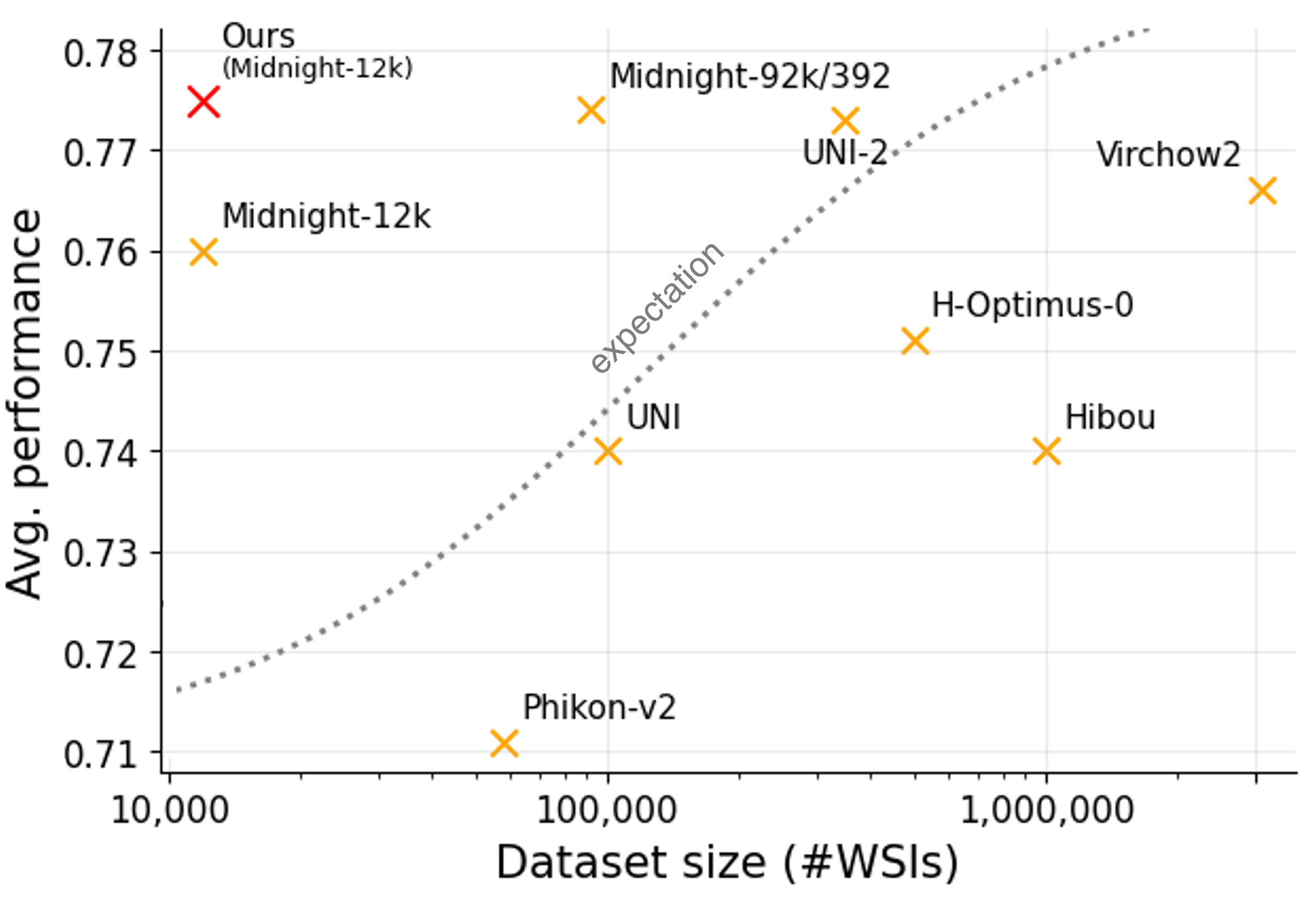
These observations reveal some of the limitations of the current state of the field. We come to two conclusions. First, OpenMidnight demonstrates that we can push foundation models on limited data much further than previously thought. Second, the messy performance landscape points to a broader concern: whether these benchmarks are truly reflective of real-world use-cases. Perhaps performance completely changes when applied to more sophisticated downstream use-cases beyond linear probes on basic classification tasks. Additionally, we note that datasets used for benchmarking are often low-quality or are improperly preprocessed during benchmark evaluation. For instance, we observed that vision transformers pretrained only on ImageNet (i.e., a model that has never seen a pathology slide) can actually outperform all pathology foundation models on the MHIST dataset.
Open-sourcing the full pipeline
We believe that fully open-sourcing the code, weights, and evaluation scripts lowers the barrier to entry, and accelerates progress in CPath with improved trust and reproducibility.
We hope that OpenMidnight will serve as an accessible baseline for pathology foundation models, and our open-source training pipeline will expand participation in the development of the next generation of pathology foundation models. Students, clinicians, and researchers without access to large compute clusters or private datasets can work together with us on methods to improve the field for everyone.
We request the CPath community to experiment with OpenMidnight and test out the model in their own research, and share any interesting results with us in the MedARC community Discord server here.
We are also building in public and welcome collaborators of all forms in the MedARC Discord server as we develop our next model, one that will deviate further from prevailing recipes to hopefully deliver larger practical gains (including better whole-slide context and a DINOv3 backbone).
Additionally, we are hiring a founding pathology foundation models research lead. If this is your area, see the full role here.
Finally, if you are a life sciences company/startup, hospital, clinician, etc. interested in applying our models to your own use cases, contact us here.