TL;DR. Today we're releasing Medmarks v1.0, a major expansion of our open-source evaluation suite for medical LLMs. It now covers 30 benchmarks, 61 models across 71 configurations, and spans verifiable tasks, open-ended clinical reasoning, and agentic workflows. Gemini 3 Pro Preview tops the verifiable leaderboard; GPT-5.2 tops the open-ended one. The full paper is on arXiv. Newer models will be added soon, as Medmarks will serve as a live leaderboard.
Medmarks v1.0
Today, we release a new version of our medical evaluation suite, including a preprint on arXiv and updated code. This v1.0 release is a significant upgrade in scale, reliability, and scope:
- 10 new benchmarks for a total of 30, including agentic environments, clinical note workflows, and expert-level reasoning.
- The model pool grew from 46 to 61, now including Gemini 3 Pro Preview, GPT-5.2, GLM 4.7, and a variety of new open-weight models.
- We move beyond the standard evaluation paradigm and demonstrate how Medmarks can be leveraged to train models through reinforcement learning.
- Tool use is now part of the benchmark through MedCalc-Bench, to assess how models behave when provided with external tools.
- Our LLM-as-a-judge approach now relies on multiple judge LLMs to increase reliability and reduce potential model biases.
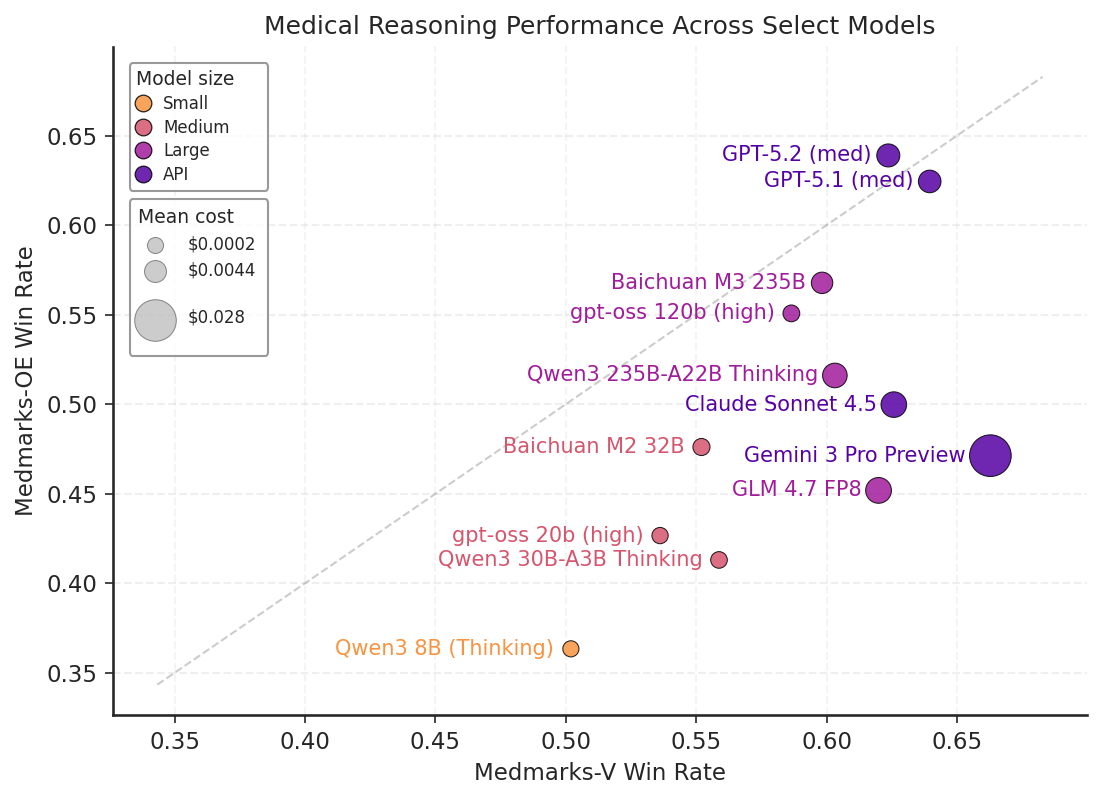
Figure 1: Results on Medmarks-V and Medmarks-OE for subset of models evaluated on both benchmarks.
Why Medmarks?
The rapid deployment and adoption of LLMs in clinical practice has outpaced the evidence around their capabilities, in large part due to the difficulty of creating reliable and exhaustive evaluations. Multiple approaches have been proposed to solve this problem, but they all suffer from limitations that prevent model developers from actually using these evaluations during development. For instance, MedHELM introduced by Stanford
Our goal with Medmarks is to offer a test environment that is simultaneously (1) fully open, with no gated datasets, (2) broad enough to cover realistic clinical tasks beyond multiple choice, (3) large enough in model coverage to support meaningful cross-model comparisons, and (4) structured so the same infrastructure supports both evaluation and post-training.
The v1.0 leaderboards
Rankings use a weighted mean win rate. Switch tabs between the verifiable subset (Medmarks-V) and the open-ended subset (Medmarks-OE).
| Model ↕ | Size ↕ | Win rate (%) ↓ |
|---|
Key takeaways
Medical fine-tuning matters
It's commonly debated whether general-purpose LLMs are sufficient for medical use
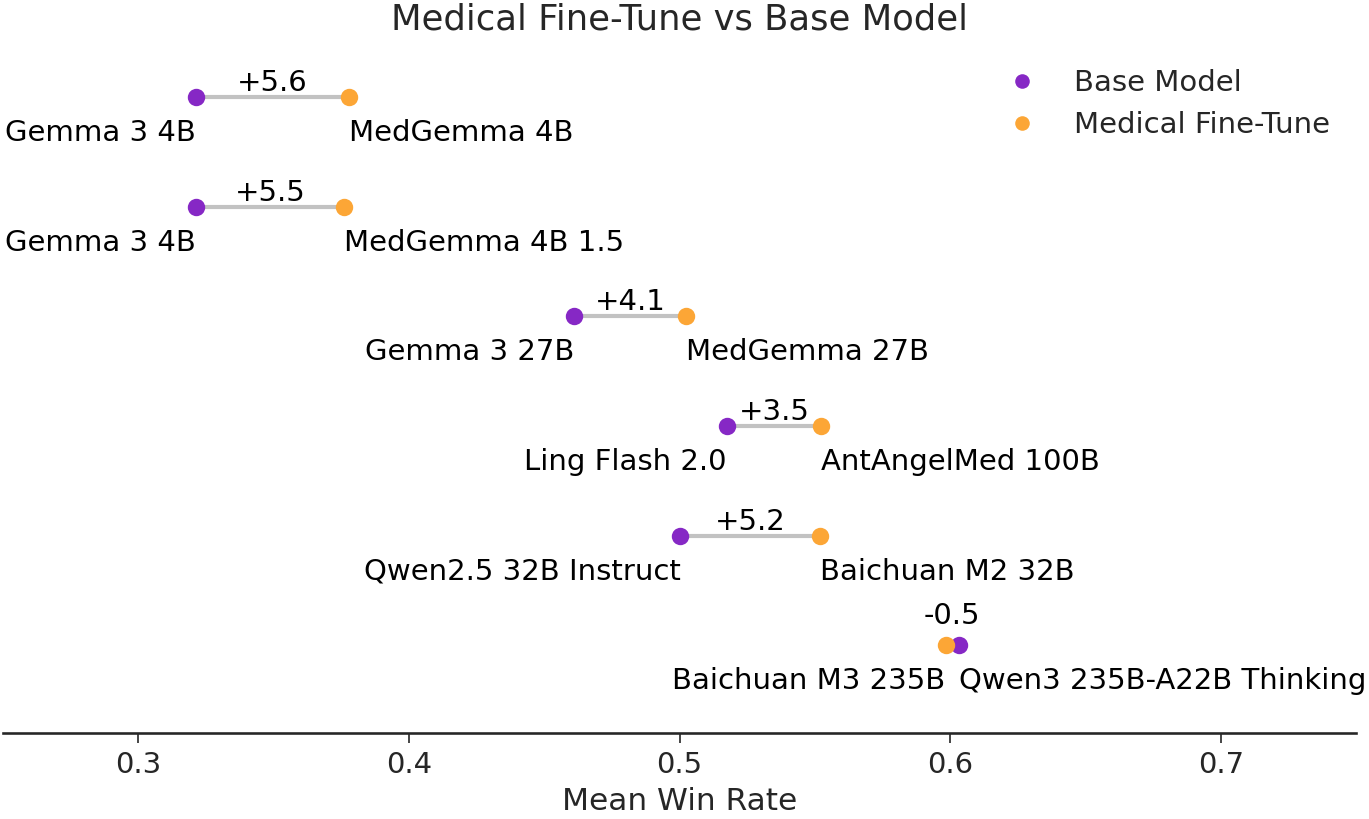
Figure 2: Win-rate change between medical fine-tunes and their base models.
The proprietary–open gap remains in medicine
While the largest open models we tested, like GLM 4.7, are approaching the frontier on the mainly multiple-choice question Medmarks-V benchmark, the proprietary–open gap reappears in the harder Medmarks-OE benchmark, which contains open-ended medical questions and agentic workflows.
Furthermore, open models have another Achilles heel: efficiency. To illustrate, GLM 4.7 and GPT-5.2 in Medmarks-V are almost identical, but GLM 4.7 requires over 5× the number of tokens to get there. We also see notable differences between proprietary models: Grok 4 and Gemini 3 Pro Preview use larger reasoning token budgets than GPT models, with Grok 4 costing roughly an order of magnitude more per query than GPT-5.1.
These findings reveal a major limitation for open-weight model deployment in clinical settings, where time and cost are of the essence.
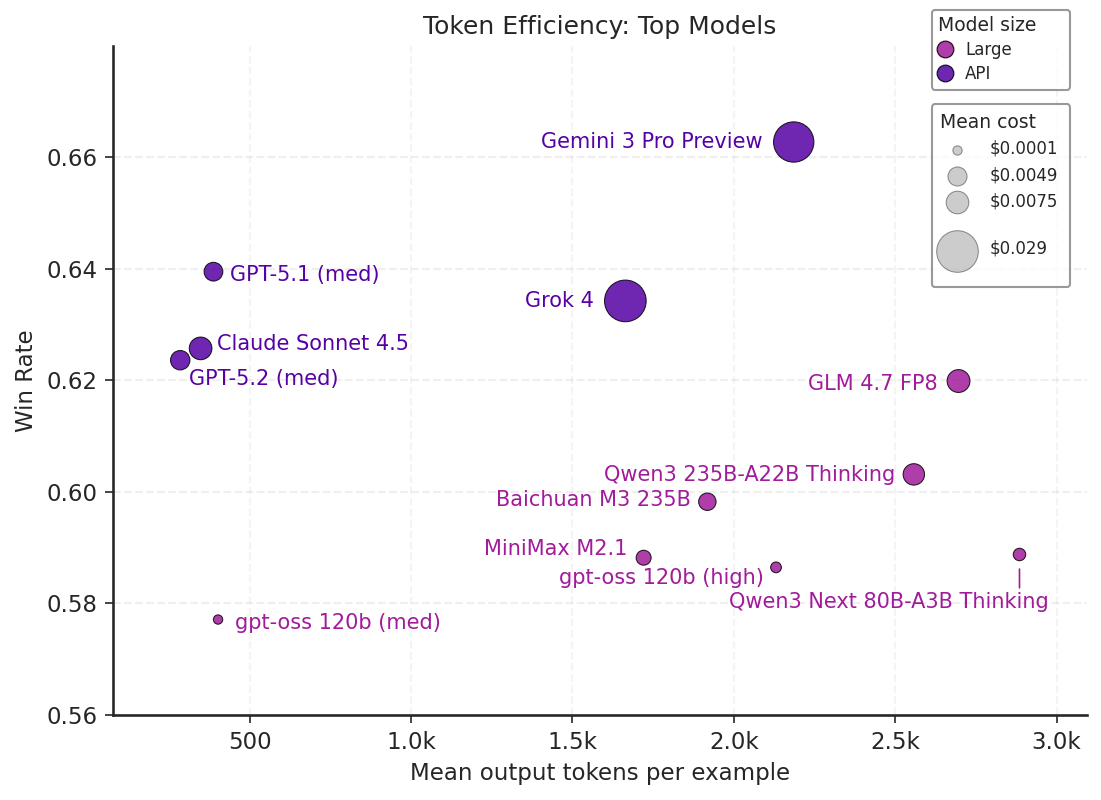
Figure 3: A scatter plot of mean win rate on Medmarks-V by tokens for top 12 models evaluated.
Reasoning budgets help
OpenAI's gpt-oss models expose reasoning effort as a low/medium/high dial, which lets us test the effect of more reasoning tokens in a controlled setting. Increasing reasoning effort produces an almost Pareto improvement across datasets, with PubMedQA
These findings are interesting given that we also observe that models tend to "overthink" questions they fail to answer correctly. Since accuracy improves with reasoning budget overall, it appears that models naturally reason longer on harder questions, but eventually still fail to answer some of them appropriately.
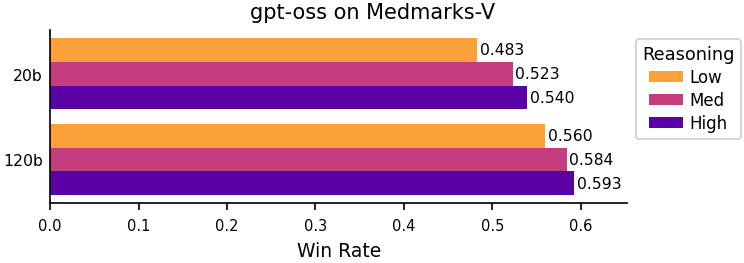
Figure 4: Win-rate change between gpt-oss reasoning level.
Multiple-choice questions reveal structural biases
We ran three rollouts of nearly every multiple-choice benchmark: one with the original order and two with shuffled answer positions. The variance reveals that multiple-choice answer order still affects modern LLMs, including frontier ones.
The most striking case is Grok 4 on M-ARC
The Medbullets
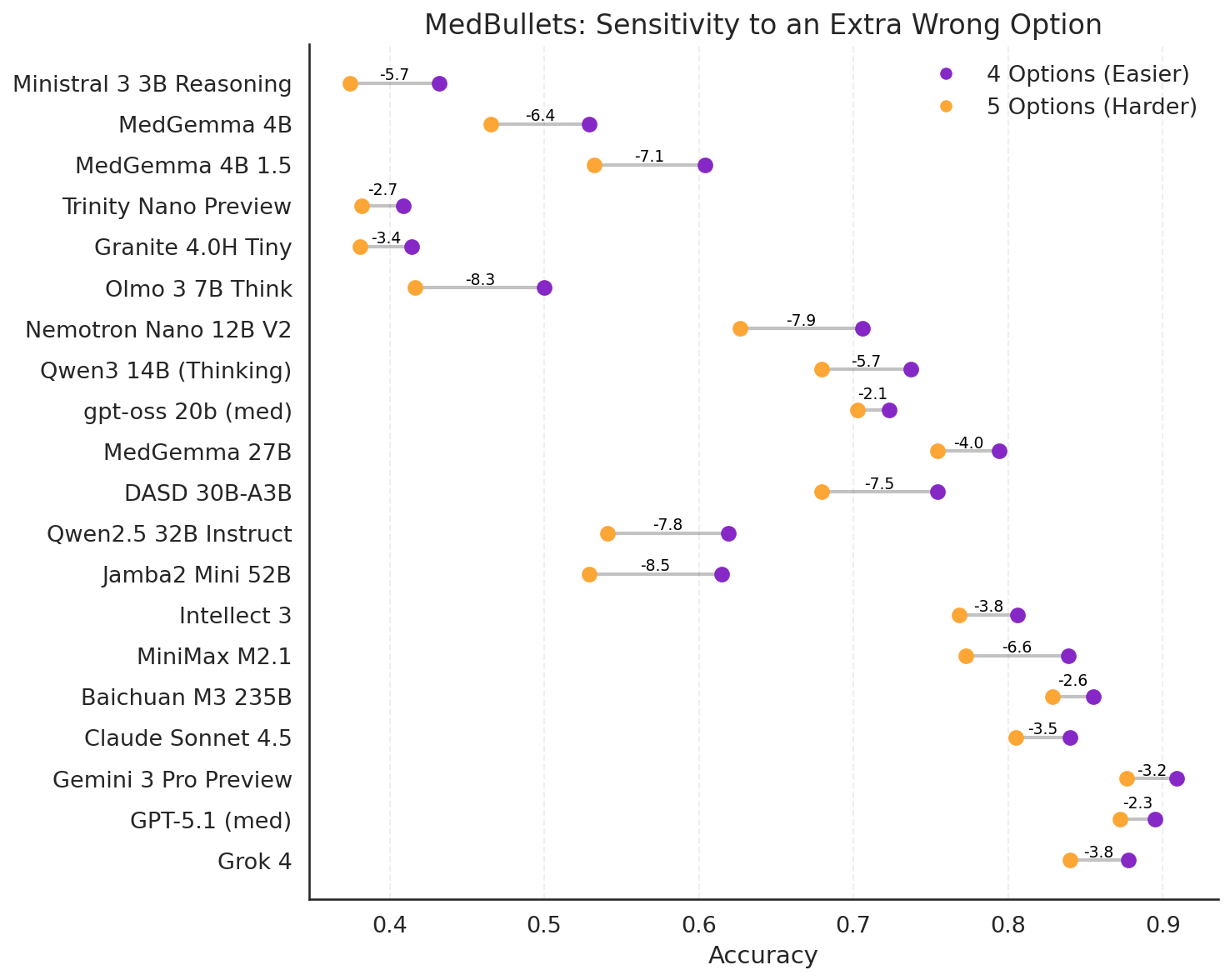
Figure 5: Comparing model performance with and without an extra option on the Medbullets
External tools sometimes hurt models
For v1.0 we ran MedCalc-Bench
Some models improve substantially with tools — MiniMax M2, Qwen3 VL, Mirothinker 1.5 30B, Olmo 3 7B. But many regress, and the failure modes are informative:
- Qwen Instruct models (across generations and quantization levels) often used tools to derive wrong answers, or overrode correct tool results with their own wrong answers.
- Many models never called tools at all and produced worse answers than without the tool option.
- Baichuan M3 appears to have lost tool-calling capability during medical fine-tuning from Qwen3 235B-A22B Thinking.
- Gemini 3 Pro Preview rejected correct tool results 13 times, apparently confident in its own wrong answer.
- GLM 4.7 FP8 regressions were mostly formatting failures — it struggled to produce parseable answers when given tools.
The takeaway: tool use isn't a free capability upgrade. The combination of tool templates, chat-completion replay semantics, and instruction-following can introduce new failure modes that offset the benefits of actually having a calculator.
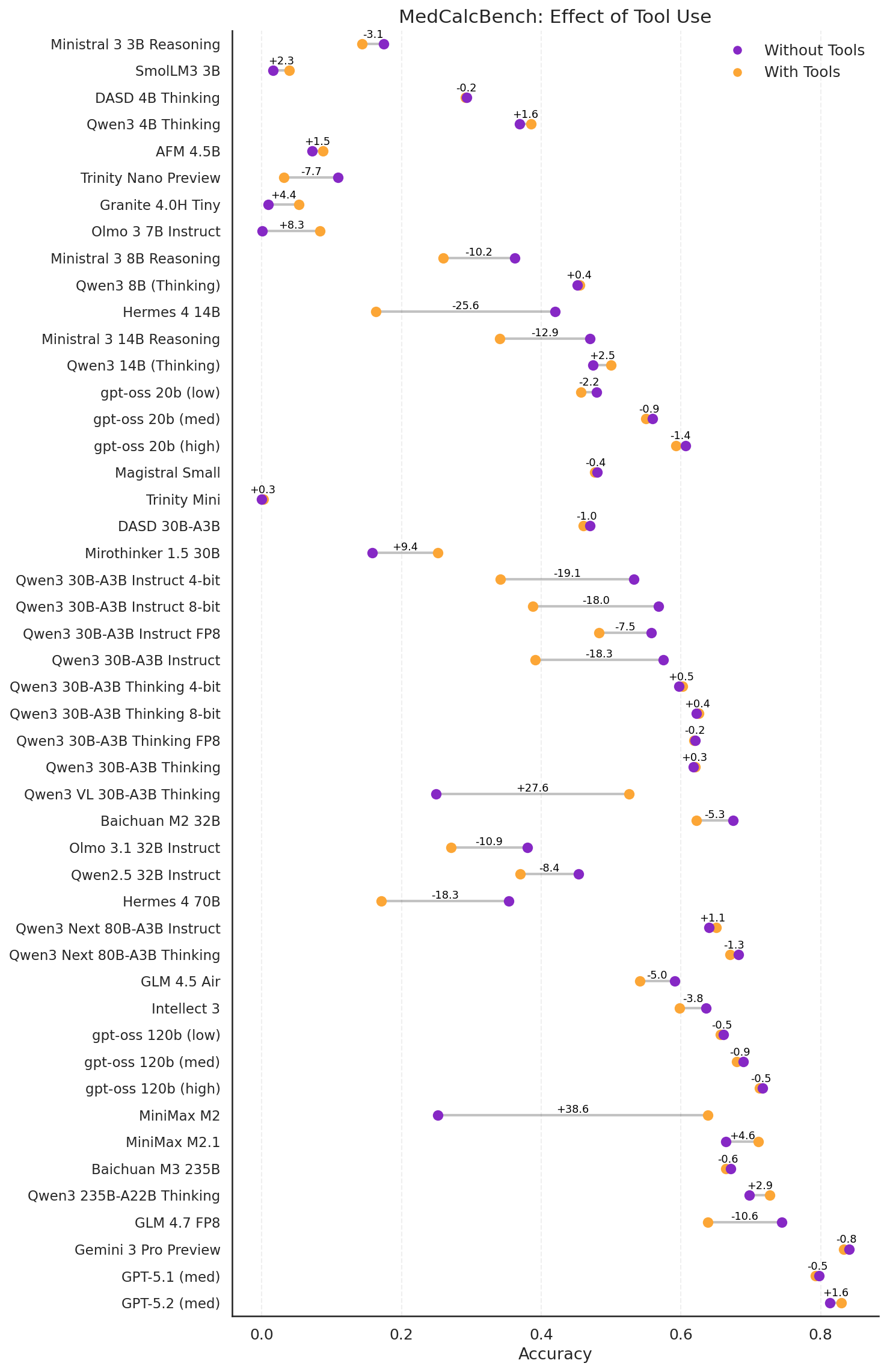
Figure 6: MedCalcBench with and without tools.
Medmarks-T: A Training Environment
One of our goals with Medmarks was to build infrastructure that supports both evaluation and post-training from the same codebase. The seven benchmarks with train/test splits — MedQA
For v1.0 we ran a very preliminary RL post-training demonstration on Qwen-3-4B-Instruct-0725 across three datasets with different reward formulations: MedCalc-Bench-Verified (calculation verifier), MedMCQA (multiple-choice matching), and MedCaseReasoning (LLM-as-a-Judge). All three show clear learning curves over 560 training steps on 8 H100s.
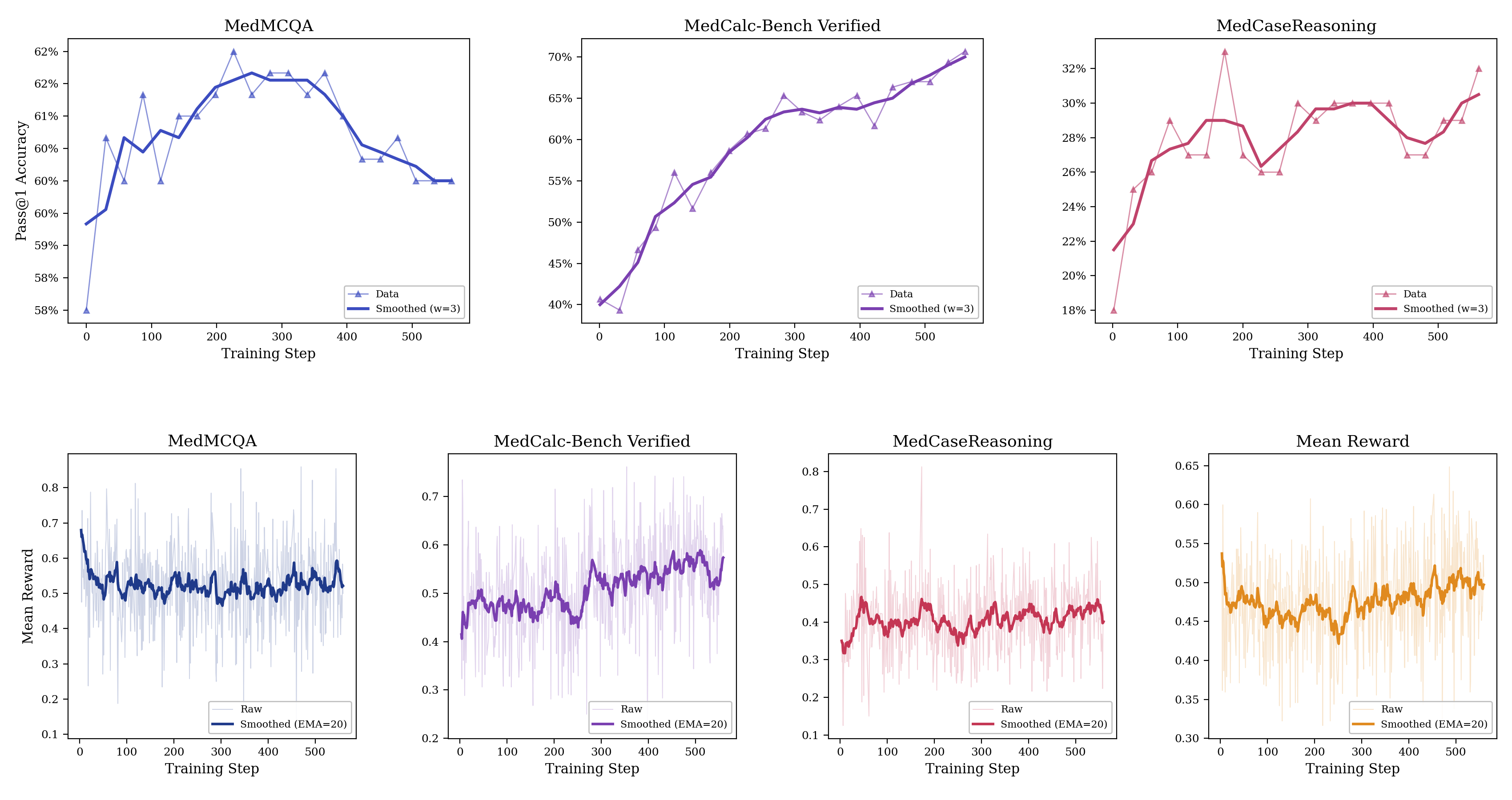
Figure 7: Test accuracy and training reward for Qwen-3-4B-Instruct-0725 trained on MedCalc-Bench-Verified, MedMCQA, and MedCaseReasoning over the course of training for 560 steps.
Conclusion
There are many more results in the main paper and earlier blog post, check it out!
We hope our benchmark suite brings us closer to real-world assessment of LLM medical capabilities in a more reproducible and accessible manner. We will continue to add new models to the benchmark suite (if you’re a model developer, please get in touch with us!) to evaluate the progress of medical capabilities in LLMs.
We are also exploring medical-specific post-training to further improve the performance of open-source LLMs. Medmarks-T is just a starting point, we are planning to construct various datasets/environments and experimenting with different post-training methods. If you are interested in such research, be sure to join https://medarc.ai and contribute!