Dec 2025 · Sophont
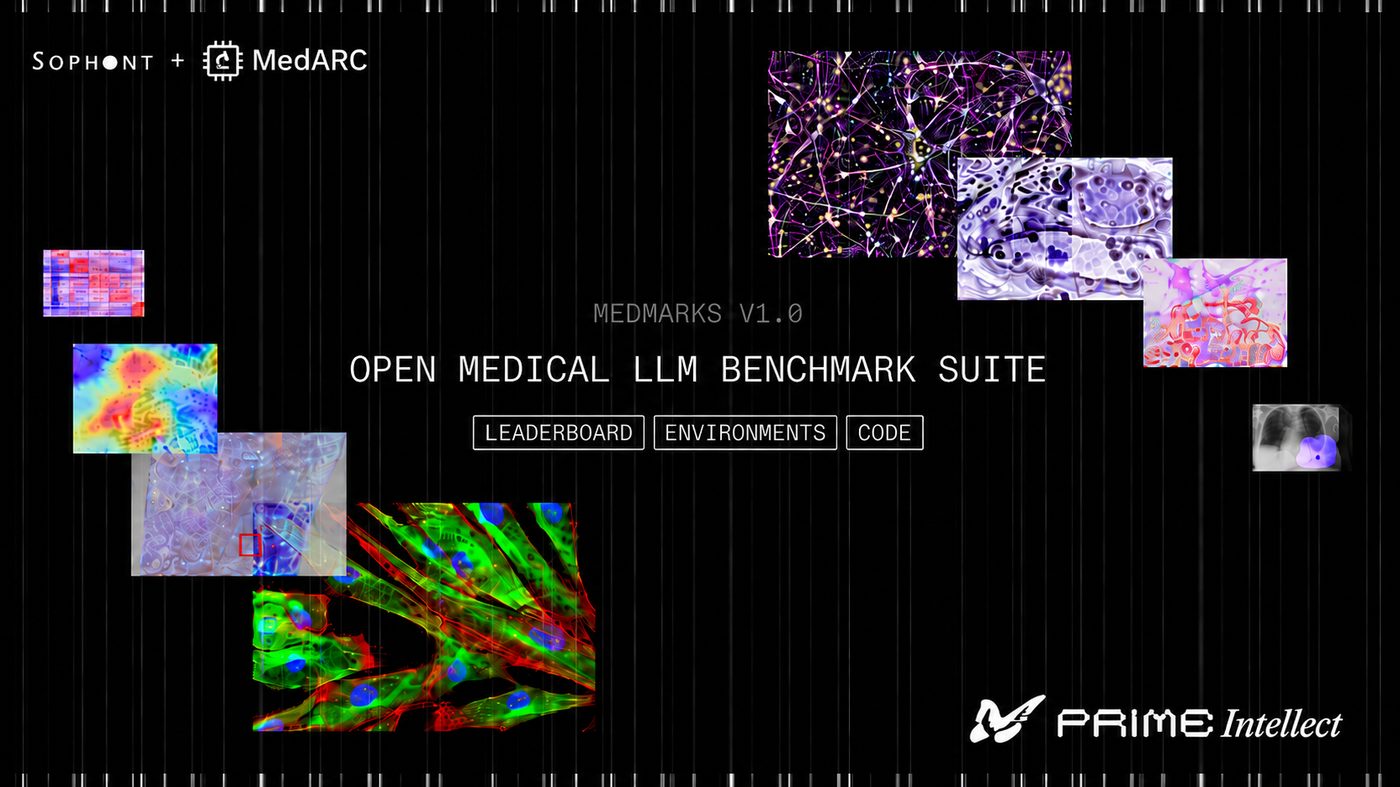
Medmarks v0.1: A comprehensive open-source LLM benchmark suite for medical tasks
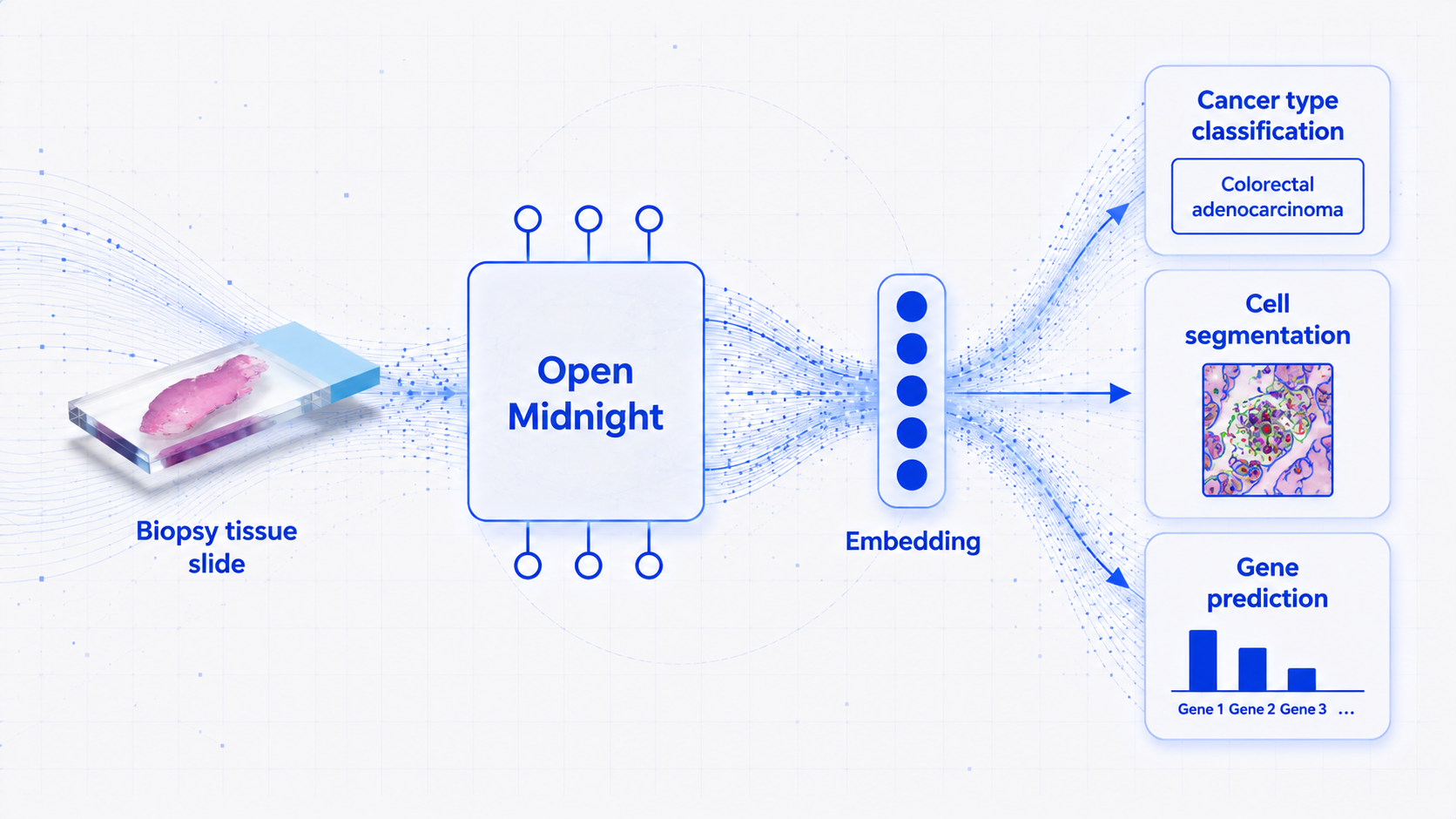
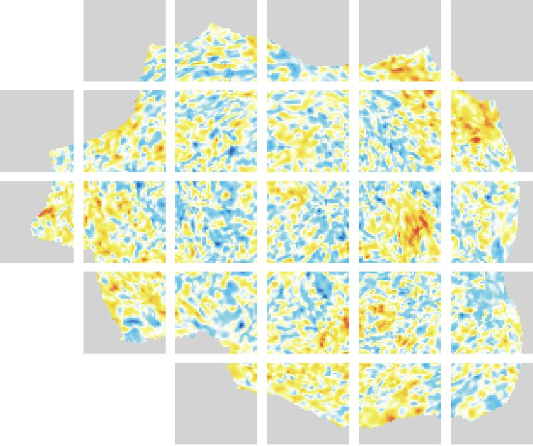
Medmarks v0.1 introduces an open benchmark suite for verifiable and open-ended medical LLM evaluation. This earlier release is distinct from Medmarks v1.0 and analyzes model accuracy, cost, reasoning behavior, quantization, prompt sensitivity, and why the datasets can double as reinforcement-learning environments.
Read ->